What AI models need to reach their full potential


LLMs have proven to be geniuses at solving certain problems, from cracking 80-year-old mathematical mysteries to migrating massive legacy codebases onto modern platforms. Then you ask Claude to do something simple, like format a spreadsheet, and it can't get it right no matter how you prompt it.
In a world where the frontier labs are improving their models at an unbelievable rate, why don’t LLMs seem good enough to rely on for everyday tasks and routine knowledge work?
It helps to consider how humans actually get things done. A knowledge worker has tools. They have memory, so they don't solve every task from scratch and can pull up context from past work as needed. And they have a place to work, such as a PC or phone where they can create, edit, duplicate, delete, and publish as the task requires.
Agents need the same. Model quality still matters, especially as each new generation unlocks harder tasks and works more reliably on its own. But another variable is becoming just as important to getting the best out of frontier models: the harness.
The harness is everything around the model that turns a model call into an agent that can do real work, including context management, memory, sandboxing, observability. The model provides the reasoning; the harness decides whether that reasoning becomes an action.
A year ago, most of our conversations with founders were about orchestration frameworks and MCP-adjacent tooling. This year we've met with more than 100 agent-infra companies, a growing share of which aren't building agents at all. They're building the harness.
We think this ends with agents becoming something professionals manage rather than tools they open. Engineers, recruiters, and analysts will each run their own agents at work, interacting with them through Slack or whatever interface they prefer.
This post covers what a harness is, why it's become the topic, and who's building it.
What is an Agent Harness?
An agent is not just a model call. A model call takes an input and returns an output. An agent has to keep working after that first output: decide what to do next, call tools, read the results, update its state, judge whether to continue, and know when to stop or ask for help.
The harness is the system that manages that loop.
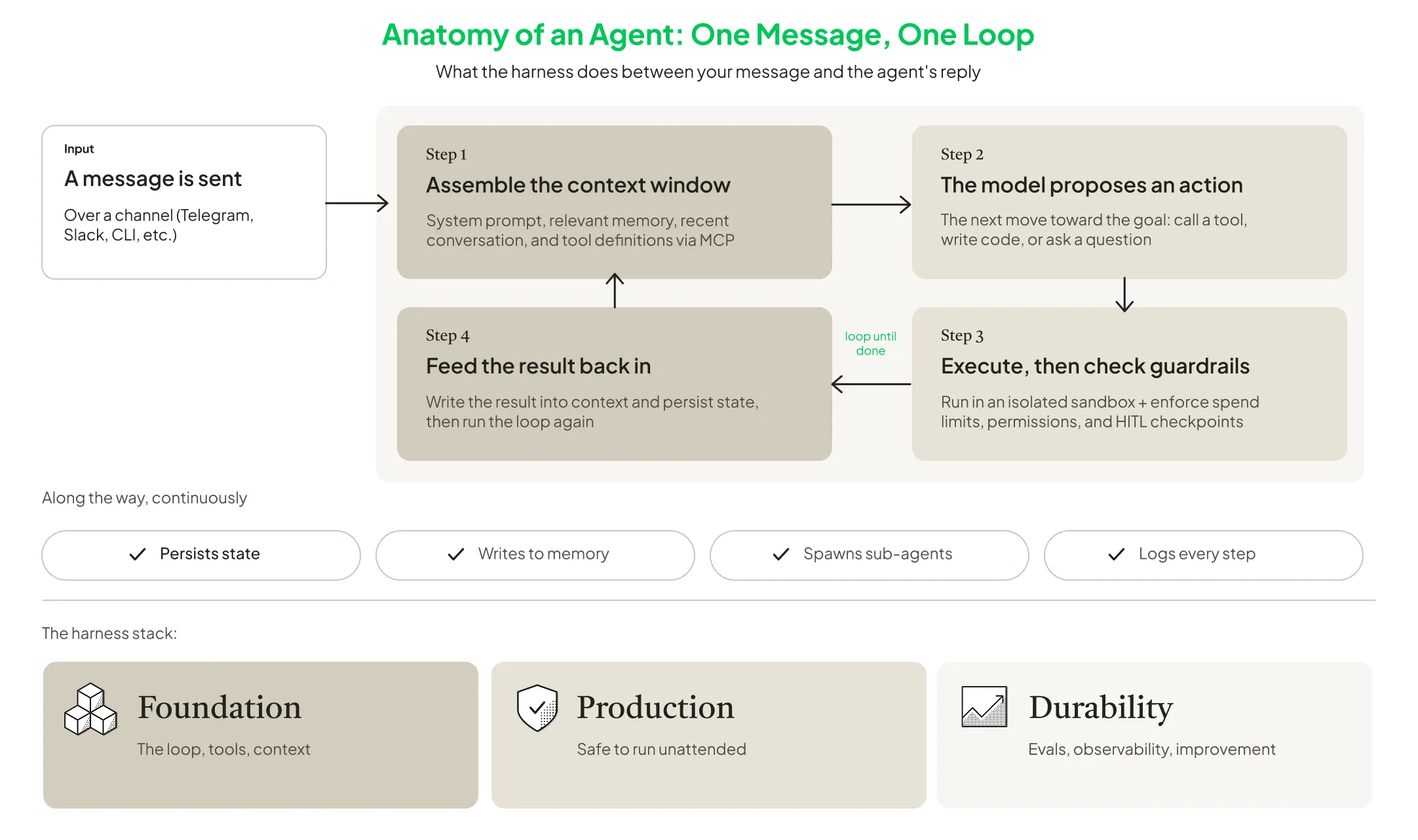
When a request comes in through Slack, Telegram, a browser, an IDE, a CLI, or a desktop app, the harness manages everything between the message and the reply. It does five things:
- Builds the context: It assembles the system prompt, task history, relevant memory, user preferences, available tools, credentials, policies, and prior actions.
- Asks the model for the next step: The model proposes an action: call a tool, write code, browse the web, ask a clarifying question, delegate to a sub-agent, or return an answer.
- Checks and executes the action: The harness decides whether the action is allowed, whether it needs human approval, what permissions apply, what budget remains, and where it should run.
- Feeds the result back into the loop: The output of the tool call, code execution, or API request becomes a new observation. The harness adds it to context and asks the model what to do next.
- Logs, evaluates, and improves: It records traces, costs, errors, outcomes, memory updates, approvals, and failures — the raw material for debugging, evals, regression tests, and training data.
That is why the same model can feel very different inside two different products. One product may give the model better repo context. Another may have safer tool permissions. Another may have better memory. Another may recover better from failed tool calls. Same model, different harness, different product.
Why this matters now
First, harness changes are moving benchmarks even when the model is fixed. LangChain moved its own coding agent from 52.8% to 66.5% on Terminal Bench 2.0, going from top 30 to top 5 while using the same model. The changes were system prompts, tools, and middleware. In other words, the harness changed. We saw another example: a team took GPT-5.5 (the current leader on Terminal-Bench 2.1) and added only one harness component: Sentra’s Code Memory. The result was 88.31%, ahead of both Anthropic’s Fable 5 (80.5%) and Mythos 5 (88.0%), while being 3.65× cheaper and using 41.2% fewer tokens. All from a single task-scoped memory layer that prevents the agent from re-reading context it already has. These kinds of gains show why harness engineering is quickly becoming the highest-leverage work in the entire stack.
Second, production failures are showing that agent risk often lives outside the model. Gartner predicts that by 2027, 40% of enterprises will demote or decommission autonomous AI agents due to governance gaps identified only after production incidents. Additionally, HCLTech's May 2026 survey of 467 senior executives at $1B+ enterprises found nearly 43% of major AI initiatives are expected to fail, attributing the risk to execution and organizational readiness rather than access to tools. The Replit and Cursor agent incidents made this failure mode more apparent. In both cases, an AI coding agent was given access to a real software environment and ended up deleting production data. The issue was not that the model lacked reasoning ability. The issue was that the system around the model allowed too much freedom and was inherently missing the environment isolation, permission boundaries, and grounding that a harness exists to provide.
Third, the harness components are already becoming markets. A year ago, teams building agents often had to assemble their own sandbox, memory layer, tool auth, and eval infrastructure. In our own meetings over the last two quarters, roughly a third of agent-related companies were not building agent applications at all. They were building pieces of the platform agents run on, including sandboxes, memory, tool auth, browser infrastructure, evals, observability, gateways, governance, and runtime infrastructure. A few weeks ago, we saw another example: a team took GPT-5.5 and added only one harness component: Sentra’s Code Memory. The result was 88.31%, ahead of both Anthropic’s Fable 5 (80.5%) and Mythos 5 (88.0%), while being 3.65× cheaper and using 41.2% fewer tokens. All from a single task-scoped memory layer that prevents the agent from re-reading context it already has. These kinds of gains show why harness engineering is quickly becoming the highest-leverage work in the entire stack.
Agent Infra Stack
A useful way to think about the harness is as the control layer between the user, the model, and the outside world. The harness divides into three functional layers.

- Foundation (Loop, Tools, Context): This is the core component to the stack. It connects the model, registers tools, controls the context window, and manages the turn-by-turn agent loop. No agent exists without this layer, but generic versions of it are likely to be built by open source frameworks and first-party lab products.
- Production (Safety for Unattended Operation): This layer makes an agent safe enough to run while the user is not watching. It includes sandboxes, identity, permissions, spend limits, durable state, memory, rollback, human-in-the-loop checkpoints, and environment separation. This is where demos become deployable systems.
- Durability (Evals, Observability, Improvement): This layer answers whether the agent is getting better or just getting used. It includes traces, replays, regression tests, benchmark environments, feedback loops, and the RL or fine-tuning infrastructure that converts usage into product improvement. This is where long-term compounding can happen.
From there, each layer is becoming its own Market. The important thing is that the stack is no longer just “model wrapper”, and that it’s changing into a section of infra markets around agent execution. Here are some of the players:

Where the Harness Becomes the Product
Once the harness exists, agents start to sort by the surface where users delegate work.
Some agents start in the IDE. Some start in the browser. Some start in Slack or Telegram. Some start on the desktop. Some are local-first. Some are designed to work across all of these surfaces.
The surface determines the initial wedge. The harness determines whether the agent retains users.
A messaging-native agent without memory becomes a chatbot. A browser agent without reliable state management becomes brittle. A coding agent without sandboxing can become dangerous. A desktop agent without permissions and audit logs is hard to trust. In each case, the product experience is determined less by the chat interface and more by the harness underneath it.
The clearest version of this is the omni-surface agent.
An omni-surface agent is not just a chatbot you message, a browser agent that clicks around, or a desktop agent that watches your screen. It needs to take a message from Slack, Telegram, WhatsApp, a CLI, or an IDE; pull context from email, calendar, docs, browser state, repos, CRM, or internal tools; execute the task somewhere safe; ask for approval when needed; update the right app; remember what happened; and report back wherever the user started.
That is the full harness showing up as one agent identity across apps.

Conclusion
The model used to be the main thing that decided whether an AI product worked. For agents, that is becoming less true. The model still matters, but the bigger question is shifting to what sits around it: the context it gets, the tools it can use, the permissions it has, the environment it runs in, the memory it keeps, the approvals it asks for, and the traces it leaves behind.
This is why the agent stack is starting to look less like a market of wrappers and more like a market of infrastructure. The same thing is happening at the application layer. Coding agents, browser agents, messaging-native agents, desktop agents, and omni-surface agents are not just competing on which model they use. They are competing on whether their harness makes them useful enough to trust with real work. A coding agent needs repo context, terminal access, test loops, protected files, and rollback. An omni-surface agent needs memory, app context, approvals, and the ability to move between Slack, email, calendar, docs, browser, and internal tools without losing state. The product may look like a chat window, an IDE sidebar, or a desktop app, but the product quality comes from the harness underneath.
But managing agents will not look like writing longer and longer prompts. It will look more like writing the onboarding doc just like a new employee: the context, preferences, decision frameworks, permissions, standard procedures, and examples that teach the agent how to work for you.
If you are building any piece of the agent stack, I would love to chat :) Please reach out to me at claire@scalevp.com
News from the Scale portfolio and firm